😰 Nỗi đau của doanh nghiệp
Thu thập dữ liệu web thủ công vẫn là một trong những gánh nặng lớn nhất của đội vận hành:
- Thu thập thủ công tốn nhiều thời gian: Phần lớn đội vận hành vẫn thu thập dữ liệu web thủ công, ghép CSV bằng tay rồi lại nhập vào Google Sheets và Excel, khiến quy trình trùng lặp, dễ sai cột và tốn nhiều giờ công mỗi tuần.
- Thiếu cơ chế khử trùng lặp: Khi không có cơ chế khử trùng lặp và nhật ký phiên, cùng một URL có thể được thu thập nhiều lần dẫn đến phình dữ liệu, sai lệch báo cáo và khó truy vết khi cần so sánh ngày-qua-ngày.
- Rủi ro bị chặn cao: Crawler hoạt động không tôn trọng robots.txt hoặc gửi quá nhiều yêu cầu đồng thời sẽ dễ bị 403/429, làm pipeline thiếu ổn định và có nguy cơ vi phạm chính sách website đích.
🎯 Vấn đề cần ưu tiên xử lý
Để giải quyết các nỗi đau trên, doanh nghiệp cần tập trung vào 3 vấn đề then chốt:
- Chuẩn hóa đầu vào: Doanh nghiệp cần một đường ống chuẩn biến dữ liệu không cấu trúc thành bảng có schema thống nhất, kèm khóa khử trùng lặp theo URL và timestamp để bảo toàn tính toàn vẹn qua thời gian.
- Ghi dữ liệu theo kiểu "append": Việc ghi dữ liệu phải theo kiểu "append" thay vì ghi đè, sử dụng đúng phương thức của Google Sheets API và Microsoft Graph Excel để duy trì lịch sử, thuận lợi cho kiểm toán và BI.
- Tuân thủ robots.txt: Cơ chế tuân thủ, gồm kiểm tra robots.txt và giới hạn tốc độ theo host, phải được đặt ở tầng crawl để giảm rủi ro bị chặn, tối ưu tỷ lệ thành công và bảo vệ mối quan hệ với website đích.
⚙️ Quy trình chi tiết thực hiện
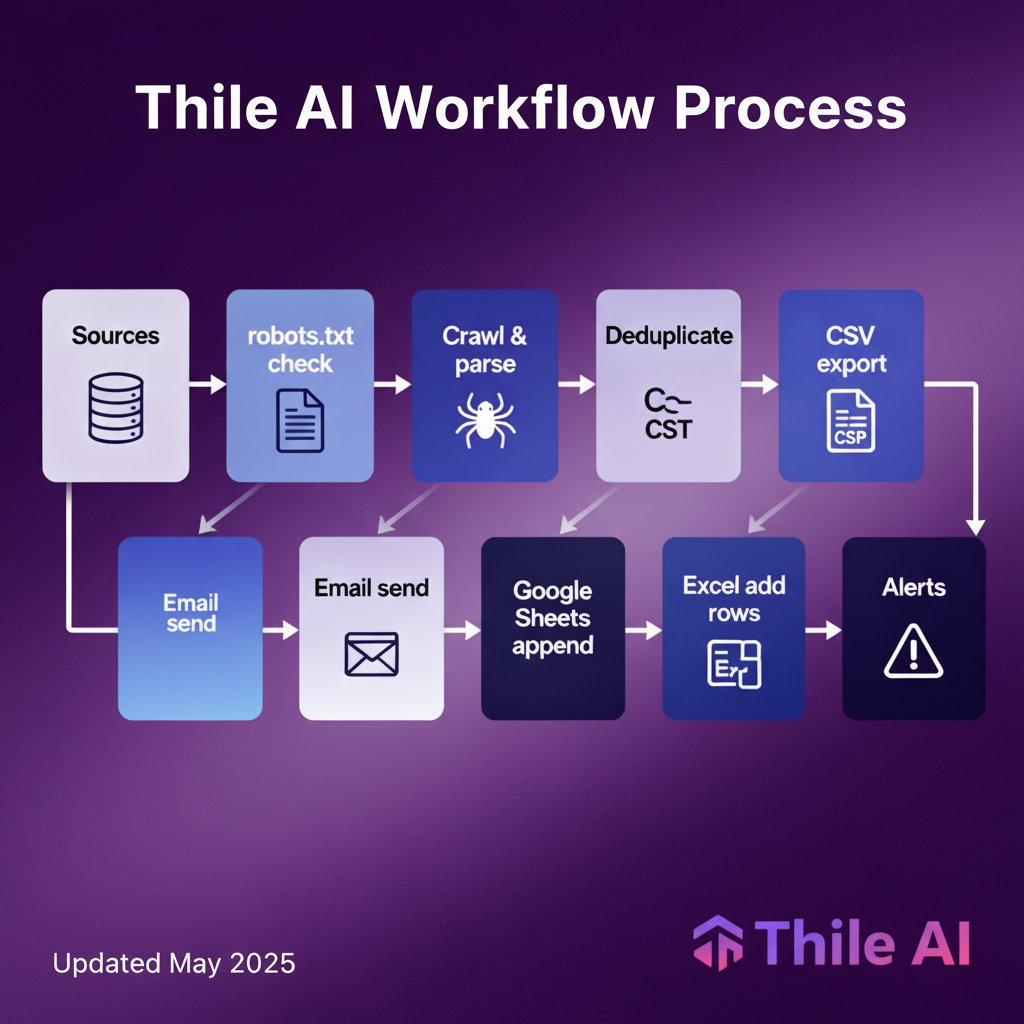
1. Lập lịch và cấu hình nguồn
Xác định danh sách URL hoặc từ khóa, gán user-agent thân thiện, cấu hình delay ngẫu nhiên và giới hạn song song theo từng domain để giảm tải đột biến.
Tuân thủ: Trước khi thu thập, đọc robots.txt của mỗi domain và chỉ crawl các đường dẫn được phép, lưu log quyết định Allow/Disallow cho mục đích kiểm toán.
2. Thu thập và trích xuất
Dùng CSS/XPath/regex để lấy các trường như tiêu đề, giá, xếp hạng, liên kết chi tiết; chuẩn hóa định dạng số/ngày và loại ký tự ẩn để dữ liệu sẵn sàng cho báo cáo.
Khử trùng lặp: Thiết lập khóa trùng lặp như URL + ngày hoặc ID nội bộ của trang, loại bản ghi lặp và ghi số lượng bản ghi bị loại vào nhật ký chất lượng.
3. Tạo CSV và gửi email
Kết xuất CSV UTF-8 in-memory, đảm bảo ký tự xuống dòng bảo toàn khi mã hóa base64 để đính kèm, tránh lỗi "mất line break" khi mở bằng các trình đọc khác nhau.
Email reporting: Gửi email kèm CSV cho nhóm phụ trách với tiêu đề chứa ngày/ca, đồng thời log người nhận, kích thước tệp và mã lỗi để hỗ trợ cơ chế retry có backoff.
4. Ghi Google Sheets (append)
Gọi phương thức spreadsheets.values.append với range đích và valueInputOption phù hợp để Sheets tự diễn giải kiểu số/ngày, giúp thêm dòng mới mà không ghi đè.
Lưu lịch sử: Khi cần chèn giữa bảng hoặc đổi layout, sử dụng hướng dẫn "Read & write cell values" và batchUpdate để bảo toàn lịch sử và tính tương thích ngược.
5. Ghi Excel Online (Microsoft Graph)
Tạo Table trong workbook một lần, sau đó dùng API add rows để thêm một hoặc nhiều hàng trên OneDrive/SharePoint, ưu tiên batch để cải thiện hiệu năng.
Best practice: Microsoft khuyến nghị thêm nhiều hàng trong một call thay vì từng hàng đơn lẻ để tránh ảnh hưởng hiệu năng và giới hạn tốc độ.
6. Giám sát và cảnh báo
So sánh số bản ghi và tỉ lệ lỗi giữa các phiên, nếu giảm bất thường hoặc tăng lỗi 4xx/5xx thì tự động gửi cảnh báo kèm mẫu HTML để rà selector.
Độ tươi dữ liệu: Theo dõi khoảng thời gian từ khi crawl xong đến khi dữ liệu có mặt trong Sheets/Excel, nhằm đáp ứng SLA dashboard nội bộ.
⚖️ Ưu nhược điểm của giải pháp
✅ Ưu điểm
- Một lần phát hai đích: Dữ liệu vừa được gửi CSV qua email, vừa append vào Google Sheets và Excel, loại bỏ bước nhập tay.
- Bền vững và có thể kiểm toán: Append và add-rows giúp bảo toàn lịch sử, với session_id và timestamp cho phép truy vết theo phiên.
- Tuân thủ và ổn định: Kiểm tra robots.txt và hạn chế tốc độ giúp giảm tỉ lệ bị chặn, tăng tính ổn định pipeline.
- Dễ mở rộng: Khi khối lượng tăng, chỉ cần điều chỉnh batch append/rows và song song crawler, không cần tăng nhân sự nhập liệu.
⚠️ Nhược điểm
- Phụ thuộc cấu trúc trang: Khi website đích thay đổi HTML, selector dễ gãy và cần bảo trì.
- Giới hạn quota API: Cả Sheets và Graph đều có hạn mức, cần gộp lô bản ghi và dùng retry-backoff.
- Ràng buộc pháp lý: Một số site hạn chế scraping, nên cần xem điều khoản sử dụng để tránh rủi ro pháp lý.
📊 Kết quả đạt được sau khi áp dụng (có số liệu cụ thể)
- Tiết kiệm thời gian: Khi thay thế quy trình thủ công bằng pipeline này, một nhóm báo cáo chạy 30 phiên/tháng có thể giảm thời gian thao tác từ 30 phút/phiên xuống còn 3–5 phút kiểm tra và duyệt, tiết kiệm khoảng 12–13 giờ mỗi tháng.
- Ghi dữ liệu hiệu quả: Append vào Google Sheets giúp thêm hàng nghìn dòng trong một phiên và trả về số ô cập nhật/updatedRange, giảm rủi ro ghi đè và tăng khả năng xác nhận kết quả ngay sau khi đẩy dữ liệu.
- Excel Online tối ưu: Thêm hàng theo lô bằng Graph vào Table giúp giữ định dạng, công thức và khả năng chia sẻ nội bộ, đồng thời rút ngắn độ trễ ghi so với chèn từng dòng.
- Khử trùng lặp: Khóa khử trùng lặp theo URL + ngày thường loại bỏ 5–15% bản ghi trùng, cải thiện độ chính xác của xu hướng và giảm thời gian làm sạch dữ liệu ở bước BI.
- Ổn định cao hơn: Kiểm tra robots.txt và đặt giới hạn tốc độ theo host giúp hạ đáng kể lỗi 403/429 trong các phiên liên tiếp, qua đó nâng SLA "độ tươi dữ liệu" và giảm cảnh báo ở dashboard giám sát.
- Dễ kiểm toán: Kết hợp session_id và timestamp cho phép đối chiếu chéo giữa CSV đính kèm, Sheets và Excel để phát hiện nhanh sai lệch, từ đó rút ngắn thời gian khắc phục khi selector thay đổi.
🎯 Kết luận
Giải pháp "crawl tuân thủ → chuẩn hóa → CSV/email → Google Sheets append → Excel add-rows" giúp số hóa toàn bộ vòng đời dữ liệu thu thập định kỳ, giảm chi phí vận hành và tăng tốc độ ra quyết định dựa trên một nguồn dữ liệu thống nhất.
Bằng việc dựa trên các chuẩn API chính thức và quy tắc robots.txt, pipeline vừa bền vững vừa thân thiện với hệ sinh thái web, tạo nền tảng vững chắc cho phân tích và tự động hóa báo cáo ở quy mô doanh nghiệp.